Tổng quan về Unicode — Thống nhất mã
Dẫn
nhập
Bảng
mã ANSI
Unicode
— Thống nhất mã
Các
ngôn ngữ, các kí tự, biểu tượng đã được mã hoá trong phiên
bản Unicode 3.0.1
Tiếng
Việt (Quốc ngữ) trong Thống nhất mã
Các
bộ chữ hỗ trợ tiếng Việt theo Thống nhất mã hiện nay
Hán
ngữ, Hán Việt
Các
bảng mã chữ Hán thông dụng
Thành
phần chữ Hán đã được thống nhất, định nghĩa trong Thống nhất
mã
Một
giải pháp mới dành cho những chữ Hán chưa được định nghĩa
trong Thống nhất mã
Tương
lai của CJKV trong Thống nhất mã
Giới
hạn hiện nay của Thống nhất mã
Tài
liệu tham khảo thêm
Dẫn
nhập
Chắc chắn
là người Việt chúng ta – ít nhất là những người thường làm
việc trên giàn máy vi tính, hoặc thỉnh thoảng sử dụng nó – đều
có lúc cảm nhận nhu cầu trao đổi thông tin, tài liệu với những
người bạn Việt ở xa qua điện thư. Nhưng một điểm cũng khá
chắc nữa là chúng ta phải đối đầu vấn đề: Làm cách nào để
trình bày văn bản tiếng Việt cho thật chuẩn xác với những dấu
hệ thuộc, sử dụng bộ chữ gì để có thể liên lạc được với
nhau? Thật là không có gì chán cho bằng phải đọc tiếng Việt không
có dấu hoặc không đọc được gì cả, bởi vì tất cả những dấu
được viết chuẩn mực bởi người viết giờ đây được thay thế
bằng những kí tự vô nghĩa trên máy của người nhận. Đối với
những người Việt trong nước thì vấn đề có vẻ không khó giải
cho lắm, bởi vì trên máy của họ ít nhất cũng có một vài Font
chữ Việt được nhiều người sử dụng; nhưng khi phải liên lạc
với người Việt hải ngoại hoặc khi Việt kiều muốn liên lạc
với nhau thì trường hợp lại hoàn toàn khác. Việc nhập chữ Việt
cũng như có một bộ chữ nhất định để có thể trình bày Việt
ngữ mà bất cứ một Việt kiều nào cũng có thể sử dụng được,
có thể đọc được quả là một vấn đề nan giải.
Cũng tương tự
việc trình bày tiếng Việt trong trường hợp nêu trên, các nước
Âu châu đều gặp »vấn đề« khi phải trao đổi văn bản với
nhau. Một nhà quản trị gửi một văn bản tiếng Tây Ban Nha đến
một người nào đó tại Hi Lạp qua dạng điện thư, để rồi
được kể lại rằng, những chữ La Tinh có dấu đã được thay
thế bằng những kí tự Hi Lạp! Còn nói gì đến đến những nước
với những ngôn ngữ, bảng chữ cái đặc thù như Thổ Nhĩ Kì,
Ả Rập, Thái Lan, và last but not least: những nước Đông á với những
chữ biểu tượng như Trung Hoa, Hàn quốc, Nhật Bản và Việt Nam,
với vô số tác phẩm chữ Nôm của ông bà tổ tiên còn phải được
khai thác, phải được nghiên cứu.
Bảng
mã ANSI
Trước hết,
chúng ta phải biết rõ hơn về bảng mã của hầu hết tất cả những
bộ chữ quốc gia cũng như quốc tế hiện nay. Đó là bảng mã
ANSI (American National Standards Institute) 8-bit với tổng cộng 256 giá
trị, tương ưng với 256 kí tự mà người ta có thể cài đặt vào.
Trong 256 kí tự
này thì chuỗi 128 kí tự đầu – cũng được biết dưới tên
ASCII (American Standard Code for Information Interchange) –, lúc nào cũng
như nhau, bởi vì chúng bao gồm bảng chữ cái La Tinh với những dấu
căn bản (từ giá trị 32-127). Các vấn đề chúng ta vừa bàn luận
bên trên không phải nằm ở đây, mà nằm ở thành phần thứ hai
của bảng mã ANSI này, từ giá trị 128-255. Nó được thay đổi tuỳ
bản ngữ của mỗi quốc gia. Và đây cũng là điểm xuất phát của
những »chướng ngại« chúng ta vừa nêu trên: Mỗi giá trị nhất
định có thể được mỗi quốc gia cài đặt một kí tự khác.
Ngay trong tiếng Việt, các bộ chữ của mỗi nhà sản xuất (VNI,
VNU, ABC, VPS, Vietware....) cũng mang một bộ mã khác nhau, chưa được
thống nhất.
Làm thế
nào để giải đáp, phục vụ nhu cầu thông tin liên lạc qua điện
thư, qua mạng quốc tế trong thời đại điện tử hiện nay? Nhìn
chung thì chúng ta phải rời bỏ hệ thống trình bày văn bản kí tự
8-bit; nó phải được nâng cấp lên để trở thành một hệ thống
16-bit với tổng cộng 65.536 (256x256) giá trị đặc thù để có thể
trình bày tất cả những ngôn ngữ thông dụng trên thế giới –
nhưng lại không mắc phải trường hợp trùng mã. Một hệ thống
như thế đã được phát triển và được biết dưới tên UNICODE
– Thống nhất biên mã (統 一 編 碼),
hoặc viết ngắn là Thống nhất mã.
Unicode
— Thống nhất mã
Thống
nhất m l g?
ما
هي الشفرة الموحدة "يونِكود" ؟ in Arabic
Co
je Unicode? in Czech
Hvad
er Unicode? in Danish
Qu'est
ce qu'Unicode? in French
რა
არის უნიკოდი? in Georgian
Was
ist Unicode? in German
Τι
είναι το Unicode; in Greek
유니코드에
대해? in Korean
Czym
jest Unikod? in Polish
Что
такое Unicode? in Russian
ソQu
es Unicode? in Spanish
Thống nhất
mã là một hệ thống có khả năng mã hoá các kí tự trên cơ sở
16-bit. Các giá trị của những kí tự được trình bày bằng một
chuỗi số Hexadecimal, bắt đầu từ U+0000 cho đến U+FFFF. Bảng mã
này ra đời nhằm khắc phục những vấn đề, những trở ngại
trong việc trao đổi thông tin, tài liệu điện tử. Thêm vào đó,
Thống nhất mã cũng hỗ trợ những ngôn ngữ cổ, bảo vệ những
di tích văn hoá của nhân loại. Trong phiên bản Unicode 3.0.1 hiện
nay, 49.194 giá trị của 65.536 đã được định nghĩa. Với số lượng
kí tự vĩ đại như thế, hầu hết các ngôn ngữ trên thế giới
đều được mã hoá một cách toàn mĩ.
Thống nhất
mã hoàn toàn tương thích bộ mã chuẩn quốc tế hiện nay là
ISO-10646 Universal Character Set (UCS). Với cơ chế mở rộng đã được
định nghĩa sẵn, bản mã 16-bit căn bản với 65.536 kí tự có thể
được mở rộng đến trên 1.000.000 kí tự, và như vậy thì tất
cả những ngôn ngữ của nhân loại xưa nay có thể được mã
hoá, có thể được bảo tàng trong thời đại điện tử ngày nay.
Hiệp Hội
Unicode (Unicode Consortium) được thành lập vào năm 1991 dưới tên
UNICODE INC., được xem là một tổ chức phi vụ lợi, nhằm hỗ trợ,
phát triển cũng như bảo vệ chất lượng của chuẩn Thống nhất
mã trong những phiên bản sau này. Thành viên của Hiệp Hội Unicode
bao gồm hầu hết các công ti sản xuất phần mềm lớn hàng đầu
trên thế giới như IBM, Microsoft, Adobe, Digital, Novell, Sun, HP,...
Các
ngôn ngữ, các kí tự, biểu tượng đã được mã hoá trong phiên
bản Unicode 3.0.1
(Bảng này
được trích từ http://czyborra.com/unicode/characters.html#extraplanes,
trang của Roman Czyborra, được sửa chữa và bổ sung.)
Basic
Multilingual Plane (BMP) 0: {U+0000..U+FFFF}
A-zone
(alphabetic): {U+0000..U+33FF}
General
Scripts Area: {U+0000..U+1FFF}
Basic
Latin (US-ASCII): {U+0000..U+007F} A B C D E .. a b c d e..
Latin-1
(ISO-8859-1): {U+0080..U+00FF} Ð Ò Ó ð ò ó
Latin
Extended A, B: {U+0100..U+024F} Ō Ā ō ā....
IPA
Extensions: {U+0250..U+02AF}
Spacing
Modifier Letters: {U+02B0..U+02FF}
Combining
Diacritical Marks: {U+0300..U+036F}
Greek:
{U+0370..U+03FF} Ά Έ Ή Ί Ϋ έ ΰ...
Cyrillic:
{U+0400..U+04FF} Ё Ђ Ѓ Є Ѕ ё ђ ѓ є...
Armenian:
{U+0530..U+058F}
Hebrew:
{U+0590..U+05FF} א ב ג ה
Arabic:
{U+0600..U+06FF} ءآأؤإئبة
Syriac:
{U+0700..U+074D}
Thaana:
{U+0780..U+07B1}
ISCII
Indic Scripts: {U+0900..U+0DFF}
Devanagari:
{U+0900..U+097F}:
Bengali:
{U+0980..U+09FF} :
Gurmukhi:
{U+0A00..U+0A7F}
Gujarati:
{U+0A80..U+0AFF}
Oriya:
{U+0B00..U+0B7F}
Tamil:
{U+0B80..U+0BFF}
Telugu:
{U+0C00..U+0C7F}
Kannada:
{U+0C80..U+0CFF}
Malayalam:
{U+0D00..U+0D7F}
Sinhalese:
{U+0D80..U+0DFF}
Thai:
{U+0E00..U+0E7F}
Lao:
{U+0E80..U+0EFF}
Tibetan:
{U+0F00..U+0FBF}
Mongolian:
{U+1000..U+109F}
Georgian:
{U+10A0..U+10FF}
Hangul
Jamo: {U+1100..U+11FF}
Ethiopic:
{U+1200..U+137F}
Cherokee:
{U+13A0..U+13FF}
Canadian
Syllabics: {U+1400..U+167F}
Ogham:
{U+1680..U+169F}
Runic:
{U+16A0..U+16FF}
Burmese:
{U+1700..U+1759}
Khmer:
{U+1780..U+17E9}
Latin
Extended Additional: {U+1E00..U+1EFF} Bao gồm những chữ đặc thù Việt
ngữ như Ạ ạ Ả ả Ấ ấ Ầ ầ Ẩ ẩ Ẫ.... cũng như những chữ
chú âm chữ Phạn, những chữ Trung đông đã được La Tinh hoá
nói chung ḍ Ḍ ḥ Ḥ ḷ Ḷ ṁ Ṁ ṃ Ṃ ṅ Ṅ ṇ Ṇ ṛ Ṛ ṣ
Ṣ....
Greek
Extended: {U+1F00..U+1FFF}
Symbols
Area: {U+2000..U+2EFF}
General
Punctuation: {U+2000..U+206F}
Superscripts
and Subscripts: {U+2070..U+209F}
Currency
Symbols: {U+20A0..U+20CF}
Combining
Marks for Symbols: {U+20D0..U+20FF}
Letterlike
Symbols: {U+2100..U+214F}
Number
Forms: {U+2150..U+218F}
Arrows:
{U+2190..U+21FF}
Mathematical
Operators: {U+2200..U+22FF}
Miscellaneous
Technical: {U+2300..U+23FF}
Control
Pictures: {U+2400..U+243F}
Optical
Character Recognition: {U+2440..U+245F}
Enclosed
Alphanumerics: {U+2460..U+24FF}
Box
Drawing: {U+2500..U+257F}
Block
Elements: {U+2580..U+259F}
Geometric
Shapes: {U+25A0..U+25FF}
Miscellaneous
Symbols: {U+2600..U+26FF}
Dingbats:
{U+2700..U+27BF}
Braille
Pattern Symbols: {U+2800..U+28FF}
CJK
Phonetics and Symbols Area: {U+2E00..U+33FF}
CJK
Radicals Supplement: {U+2E80..U+2EF3} 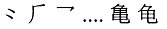
KangXi
radicals: {U+2F00..U+2FD5} 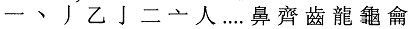
Ideographic
Description Characters: {U+2FF0..U+2FFB} 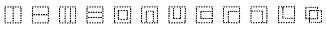
CJK
Symbols and Punctuation: {U+3000..U+303F} 、 。
〃 《 》
「 」 『
』 【 】
〖 〗
Hiragana:
{U+3040..U+309F} ぁ あ ぃ
い ぅ う
.... ゐ ゑ
を ん ゔ
Katakana:
{U+30A0..U+30FF} ァ ア ィ
イ ォ オ
カ ガ キ
ギ
Bopomofo:
{U+3100..U+312F} ㄅ ㄆ ㄇ
ㄈ ㄉ ㄊ
ㄋ ㄌ ㄍ
ㄎ ㄏ....
Hangul
Compatibility Jamo: {U+3130..U+318F} ㄱ ㄲ
ㄳ ㄴ ㄵ
ㄶ
Kanbun:
{U+3190..U+319F} ㆒㆓㆔㆕㆖㆗㆘㆙㆚㆛㆜㆝㆞㆟
Enclosed
CJK Letters and Months: {U+3200..U+32FF} ㊀ ㊁
㊂ ㊃ ㊄
㊅ ㊆ ㊊
㊋ ㊌ ㊍
㊎ ㊏ ㊐
CJK
Compatibility: {U+3300..U+33FF} ㍘ ㍙
㍚ ㍛ ...
㍱ ㍲ ㍳
㍴ ㍼ ㍽
㍾ ㍾ ...
I-zone
(ideographic): {U+3400..U+9FFF}
CJK
Unified Ideographs, Extension A: {U+3400..U+4DFF} 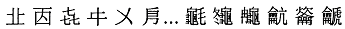
CJK
Unified Ideographs: {U+4E00..U+9FA5} 一 丁
丂 七 丄
.... 龠 龡
龣 龤 龥
龥
O-zone
(other): {U+A000..U+D7FF}
Yi:
{U+A000..U+A4C8}
Hangul
syllables: {U+AC00..U+D7A3}
S-zone
(surrogates): {U+D800..U+DFFF}
High
Surrogates {U+D800..U+DBFF}
Low
Surrogates {U+DC00..U+DFFF}
R-zone
(reserved): {U+E000..U+FFFD}
Private
Use Area: {U+E000..U+F8FF}
Compatibility
Area and Specials: {U+F900..U+FFFF}
CJK
Compatibility Ideographs: {U+F900..U+FAFF}
Alphabetic
Presentation Forms: {U+FB00..U+FB4F}
Arabic
Presentation Forms-A: {U+FB50..U+FDFF}
Combining
Half Marks: {U+FE20..U+FE2F}
CJK
Compatibility Forms: {U+FE30..U+FE4F}
Small
Form Variants: {U+FE50..U+FE6F}
Arabic
Presentation Forms-B: {U+FE70..U+FEFF}
Halfwidth
and Fullwidth Forms: {U+FF00..U+FFEF}
Specials:
{U+FFF0..U+FFFF}
UTF-16
extra planes (sẽ được phiên bản Unicode 4 and ISO-10646-2 sử dụng
và định nghĩa)
Non-Han
Supplementary Plane 1: {U-00010000..U-0001FFFF}
Etruscan:
{U-00010200..U-00010227}
Gothic:
{U-00010230..U-0001024B}
Klingon:
{U-000123D0..U-000123F9}
Western
Musical Symbols: {U-0001D103..U-0001D1D7}
Han
Supplementary Plane 2: {U-00020000..U-0002FFFF} (Đây là chỗ mã hoá bảng
mở rộng CJKV Extension B)
Reserved
Planes 3..13: {U-00030000..U-000DFFFF}
Plane
14: {U-000E0000..U-000EFFFF}
Language
Tag Characters: {U-000E0000..U-000E007F}
Private
Use Planes: {U-000F0000..U-0010FFFF}
Giá trị của
Thống nhất mã đối với các ngôn ngữ Đông á Hán, Nhật, Hàn
và Việt (Chinese, Japanese, Korean, Vietnamese [CJKV]), đặc biệt là nền
văn hoá cổ của các nước này.
Tiếng Việt
(Quốc ngữ) trong Thống nhất mã
Bảng chữ
cái tiếng Việt nằm trong thành phần Latin-1 {U+0080..U+00FF}, thành
phần Latin Extended A, B {U+0100..U+024F} với những dấu hệ thuộc nằm
ở Combining Diacritical Marks {U+0300.. U+036F} và thành phần Latin
Extended Additional {U+1E00..U+1EFF}. Đơn vị tiền tệ Việt Nam »Đồng«
₫ mang mã Hexa U+20AB.
Thống nhất
mã dành riêng hai cách trình bày tiếng Việt là tổ hợp (compound)
và dự tác (precompound) và đây cũng là một điểm đặc biệt của
tiếng Việt chúng ta so với những ngôn ngữ gốc La Tinh khác. Tổ
hợp ở đây có nghĩa là một chữ có dấu được tạo bởi 1. chữ
và 2. dấu, hai kí tự với hai mã Thống nhất khác nhau. Dự tác
có nghĩa là một chữ có dấu đã được dựng sẵn, chỉ mang một
mã Thống nhất duy nhất. Thành phần Latin Extended Additional
{U+1E00..U+1EFF} được dành riêng cho những kí tự đã được dựng
sẵn.
Sau đây là một
ví dụ để thuyết minh hai trường hợp vừa nêu trên: Chữ Ở
có thể được trình bày bằng chữ Ơ {U+01A0} và dấu ̉ {U+0309}
trong trường hợp tổ hợp, hay qua một mã duy nhất là Ở {U+1EDE}
trong trường hợp dựng sẵn.
Cả hai cách
trình bày tiếng Việt trên đều có những điểm lợi và bất lợi
riêng của chúng. Theo cách tổ hợp thì Windows2000 hỗ trợ cách sắp
xếp thứ tự chỉ mục (index), bảng chữ cái cũng như lệnh All
Caption (bắt hiển thị bằng chữ in lớn), nhưng ngược lại, thỉnh
thoảng các dấu có vẻ như tung cánh bay, mất sự tương xứng bởi
vì phần mềm điều khiển các chữ tổ hợp chưa làm việc uy tín
lắm (kinh nghiệm rút từ Office2000 dưới Win2000; WinNT hoàn toàn
không hỗ trợ chế độ tổ hợp). Thêm vào đó, chúng ta không thể
sử dụng Wordart, bởi vì hai thành phần được tổ hợp sẽ tách
lìa nhau ngay. Nhìn như vậy thì dạng kí tự dự tác có lẽ chuẩn
xác hơn, nhưng hiện nay, phần mềm hỗ trợ Thống nhất mã tối
ưu là Office2000 vẫn chưa xử lí đúng những chữ Việt dự tác đúng
tiêu chuẩn, bởi vì việc sắp xếp chỉ mục cũng như lệnh All
Caption vẫn chưa hiệu nghiệm. Hi vọng trong một ngày gần đây, tất
cả những vấn đề vừa nêu trên sẽ trở thành dĩ vãng, tiếng
Việt chúng ta có thể được trình bày một cách toàn vẹn trên mọi
hệ điều hành, dưới mọi ứng dụng.
Các bộ chữ
hỗ trợ tiếng Việt theo Thống nhất mã hiện nay
1.
Arial Unicode MS: Font này rất lớn (23 MB), chứa đựng tất cả những
kí tự đã được mã hoá trong phiên bản Unicode 2.1;
2.
Bitstream CyberBase, cũng hỗ trợ các chữ Phạn (Devanagari) đã được
La Tinh hoá;
3.
Code2000, hỗ trợ đa ngôn ngữ, bao gồm nhiều kí tự của phiên bản
Unicode 3.0;
4.
Courier New (hỗ trợ tiếng Việt kể từ phiên bản 2.72, hiện tại
là 2.82);
5.
Arial (hỗ trợ tiếng Việt kể từ phiên bản 2.72, hiện tại là
2.82)
6.
Times New Roman (hỗ trợ tiếng Việt kể từ phiên bản 2.72, hiện tại
là 2.82);
7.
Verdana (phiên bản 2.35);
8.
Tahoma (phiên bản 2.60);
9.
Palatino Linotype;
10.
Thryomanes;
11.
Titus Cyberbit Basic;
12.
Microsoft Sans Serif;
13.
Latha (hỗ trợ chữ Phạn nguyên dạng);
14.
Mangal (hỗ trợ chữ Phạn nguyên dạng);
Hán ngữ,
Hán Việt
Các chuyên
gia nhập vi tính Hán văn, đặc biệt là những người chuyên
nghiên cứu Cổ văn chắc chắn đã có lúc ngao ngán, nản chí vì
không tìm được chữ mình muốn nhập trong những bảng mã chữ
Hán hiện tại, bởi vì chúng định nghĩa quá ít chữ so với những
bộ Từ (Tự) điển lớn như Khang Hi, Từ Hải, Hán Ngữ Đại Từ
Điển, Từ Nguyên, Từ Vị... Họ phải tìm những chữ giản hoá,
thậm chí phải thay thế bằng một chữ chú âm khác (trong trường
hợp thay thế những chữ tượng thanh), hoặc phải để trống những
ô để sau đó viết tay vào; cho một văn bản điện tử như vậy
rất bất tiện. Muốn đi vào những giải pháp dành cho những nhu cầu
trên, chúng ta phải quan sát kĩ hơn các bảng mã phổ biến, nhưng
có nhiều giới hạn hiện nay.
Các bảng mã
chữ Hán thông dụng
1. Bảng mã
JIS (Japanese Industry Standard): Đây là bảng mã được phát triển đầu
tiên trên thế giới để trình bày Hán tự trên vi tính, được sử
dụng tại Nhật. Bảng mã này đã được hoàn chỉnh lại hai lần
vào năm 1983 và 1990, bao gồm khoảng 12.300 Hán tự.
2. Big 5:
Được công bố vào năm 1986, bảng mã này định nghĩa 13.051 Hán tự,
và những Hán tự này lại được chia thành hai nhóm, thường dùng
(thường dụng tự 常 用 字) và ít
dùng (thứ thường dụng tự 次 常 用 字).
Bảng mã này là bảng mã phồn thể thông dụng nhất trên mạng quốc
tế hiện nay.
4. GB
(Guóbiāo, Quốc Tiêu, là chữ viết tắt của Quốc Gia Tiêu Chuẩn 國
家 標 準): Bao gồm khoảng 7.039 Hán tự,
là bảng mã chuẩn của Trung Hoa lục địa hiện nay. Bảng mã mở
rộng của GB được gọi là GBK (Quốc Tiêu Khoáng Triển 國
標 擴 展) bao gồm phần bổ sung khoảng
14.240 Hán tự ít gặp. Bộ mã GB (GBK) này cũng được biết dưới
tên »Mã giản thể«.
Thành phần
chữ Hán đã được thống nhất, định nghĩa trong Thống nhất mã
Trong phiên bản
2.1, Thống nhất mã định nghĩa 20.902 Hán tự, và đây cũng là
phiên bản được lấy làm cơ sở cho các hệ điều hành như
WindowsNT 4.0 và Windows2000. Trong phiên bản 3.0 vừa được công bố
đầu năm 2000, Hiệp Hội Unicode đã chính thức định nghĩa thành
phần mở rộng CJKV-Unified Ideographs Extension A, bao gồm 6.582
Hán tự.
Như vậy thì
hiện tại, Thống nhất mã đã định nghĩa 27.484 Hán tự – và như
chúng ta đã thấy –, nhiều hơn tất cả những bảng mã thông dụng
vừa nêu trên. Trong một văn bản, chúng ta có thể sử dụng chữ
Hán giản và phồn thể chung, thậm chí trong những phần mềm ứng
dụng đặc biệt, chúng ta có thể chuyển toàn bộ văn bản từ giản
sang phồn thể hoặc ngược lại, bởi vì thành phần chữ Hán
trong Thống nhất mã dung nạp cả hai bảng mã Big5 (phồn thể,
13.051 Hán tự) và GB (giản thể 7.039 Hán tự), và thêm vào những
Hán tự ít gặp với một số lượng không nhỏ.
Một giải
pháp mới dành cho những chữ Hán chưa được định nghĩa trong Thống
nhất mã
Thêm vào những
thành tựu vừa nêu trên, Thống nhất mã cũng đã định nghĩa những
Mô tả tự hình (Ideographic Description Characters) với mục đích diễn
tả những chữ Hán chưa được định nghĩa bằng chính những Mô
tả tự hình này. Dĩ nhiên, trước đây chúng ta cũng đã tìm thấy
những phương pháp mô tả những chữ chưa được mã hoá, nhưng, với
phiên bảng 3.0 với 12 Mô tả tự hình vừa được định nghĩa, các
phương pháp diễn tả những chữ chưa được mã hoá lần đầu tiên
được thống nhất. Sau đây là một vài ví dụ:
A.
Cách mô tả với những dấu hiệu thường gặp, tương đối tuỳ
tiện, chưa được thống nhất:
1.
Hồ 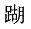 = 路 -
各 + 胡
= 路 -
各 + 胡
2.
Song 窻 = 窗/心
B.
Cách trình bày bằng Mô tả tự hình:
1.
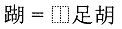
2.
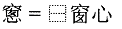
Tổng
cộng, Thống nhất mã định nghĩa 12 Mô tả tự hình
(U+2FF0-U+2FFB): 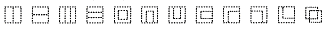 .
.
Như vậy thì
hầu hết tất cả những chữ ít thấy đều có thể được diễn
tả một cách dễ hiễu, và đồng thời, những Mô tả tự hình
này cũng giúp giữ được phần nào vẻ thẩm mĩ trong văn bản
được trình bày.
Tương lai của
CJKV trong Thống nhất mã
Theo tin của
nhóm IRG-Ideographic Rapporteur Group tại Hồng Công, một thành phần mở
rộng của chữ Hán trong Thống nhất mã với tên CJK-Unified
Ideographs Extension B đã được Hiệp Hội Unicode chấp nhận, và
nó sẽ là thành phần của một trong những phiên bản sắp tới của
Unicode, thậm chí của ngay phiên bản Unicode 4.0. Thành phần bổ
sung mở rộng B này lấy nguồn từ:
1. Tất
cả những Hán tự chưa được mã hoá trong Khang Hi Tự Điển 康
熙 字 典 cũng như Khang Hi Tự Điển Bổ
Di 《康 熙 字 典》 補 遺 (18.486 Hán
tự);
2. Tất
cả những Hán tự chưa được mã hoá trong Hán Ngữ Đại Tự Điển
漢 語 大 字 典 (28.914 Hán tự);
3. Những
Hán tự đặc thù trong: Từ Nguyên 辭 源 (66),
Từ Hải 辞 海 (247), Hán Ngữ Đại
Từ Điển 漢 語 大 辭 典 (553),
Trung Quốc Đại Bách Khoa Toàn Thư 中 國 大 百 科 全 書 (86),
Phương Chính Bài Bản Hệ Thống 方 正 排 版 系 统 (65),
Tứ Khố Toàn Thư 四 庫 全 書 (522);
4. Hán tự từ
các nước Hồng Công (1.081), Hàn Quốc (166), Nhật Bản (302), Đài
Loan (30.177), và đặc biệt là 4.232 chữ Nôm được định
nghĩa trong Tiêu Chuẩn Việt Nam TCVN 5773:1993 (và VHN 01:1998, VHN
01:1998).
Tổng cộng,
bản mở rộng CJK-Extension B trong Thống nhất mã sẽ bao gồm 42.711
Hán tự, và nếu cộng chung với những Hán tự đã được mã
hoá, chúng ta sẽ có đúng 70.195 Hán tự. Cũng nên biết thêm
là bảng mã bổ sung B này sẽ được cài đặt trên cơ chế mở rộng
UTF-16 (Universal Transformation Format 16) của Thống nhất mã (dùng một
cặp mã thống nhất được dành riêng để trình bày một kí tự
mới)
Nếu tất cả
sẽ diễn biến như trên thì có lẽ trong một thời gian gần đây,
ước mơ của nhiều nhà nghiên cứu văn hoá cổ truyền tại Việt
Nam cũng như các nước Đông á có Hán tự là gốc sẽ trở thành
một hiện thật; tất cả những văn bản, kinh điển của các bậc
Hiền nhân, các Thánh tăng sẽ được lưu lại dưới dạng điện
tử một cách toàn hảo – có phải đây là nơi »kim cổ giao
duyên« một cách toàn mĩ?
Giới
hạn hiện nay của Thống nhất mã
Sau những niềm
hân hoan khi đọc những kì tích của Thống nhất mã, chúng ta cũng
đừng quên Thống nhất mã đòi hỏi những thiết bị rất cao cấp,
bởi vì, nếu so sánh với một bộ chữ ANSI bình thường với dung
tích khoảng 50-60 Kb, một bộ chữ Thống nhất mã có thể lên đến
vài MB, thậm chí lên đến vài mươi MB tuỳ theo số lượng kí tự
trong đó. Font chữ Thống nhất mã lớn nhất hiện nay là Arial
Unicode MS của Microsoft, có dung tích hơn 23 MB! Vi tính nào không đủ
bộ nhớ sẽ bị chậm lại ngay sau khi cài đặt bộ chữ này. Thế
nên, trong tương lai gần, phần lớn chúng ta vẫn chưa đạt được
trình độ, khả năng sắm sửa những thiết bị cần thiết để sử
dụng Thống nhất mã. Nhưng, biết là có những kĩ thuật có thể
thống nhất phần nào ngôn ngữ của toàn thể nhân loại, biết
chúng có thể được hoàn thiện cũng đã là một niềm vui, và
chính bài viết này – được sáng tác với những kĩ thuật ấy
–, nó là một chứng minh cụ thể.
Tài
liệu tham khảo thêm
Sách:
1.
The Unicode Consortium: The Unicode Standard Version 3.0, Addison Wesley
Longman, Inc. 2000.
2.
Ken Lunde: CJKV Information Processing, O'Reilly and Associates, Inc.
1999.
URL:
1.
http://www.unicode.org/
2.
http://charts.unicode.org/
3.
http://www.mojikyo.gr.jp/html/abroad/abroad_top.html
4.
http://www.hclrss.demon.co.uk/unicode/fonts.html
5.
http://www.cse.cuhk.edu.hk/~irg/
6.
http://czyborra.com/unicode/characters.html#extraplanes
7.
http://www.oreilly.com/people/authors/lunde/cjkv-char.html
8.
http://jeff.cs.mcgill.ca/~luc/china.html